
Getty

This week, the AI research community has gathered in New Orleans for the International Conference on Learning Representations (ICLR, pronounced “eye-clear”), one of its major annual conferences. There are over 3,000 attendees and 1,500 paper submissions, making it one of the most important forums for exchanging new ideas within the field.
This year the talks and accepted papers are heavily focused on tackling four major challenges in deep learning: fairness, security, generalizability, and causality. If you’ve been following along with MIT Technology Review’s coverage, you’ll recognize the first three. We’ve talked about how machine-learning algorithms in their current state are biased, susceptible to adversarial attacks, and incredibly limited in their ability to generalize the patterns they find in a training data set for multiple applications. Now the research community is busy trying to make the technology sophisticated enough to mitigate these weaknesses.
What we haven’t talked about much is the final challenge: causality. This is something researchers have puzzled over for some time. Machine learning is great at finding correlations in data, but can it ever figure out causation? Such an achievement would be a huge milestone: if algorithms could help us shed light on the causes and effects of different phenomena in complex systems, they would deepen our understanding of the world and unlock more powerful tools to influence it.
On Monday, to a packed room, acclaimed researcher Léon Bottou, now at Facebook’s AI research unit and New York University, laid out a new framework that he's been working on with collaborators for how we might get there. Here’s my summary of his talk. You can also watch it in full below, beginning around 12:00.

Let’s begin with Bottou and his team's first big idea: a new way of thinking about causality. Say you want to build a computer vision system that recognizes handwritten numbers. (This is a classic introductory problem that uses the widely available “MNIST” data set pictured above.) You’d train a neural network on tons of images of handwritten numbers, each labeled with the number they represent, and end up with a pretty decent system for recognizing new ones it had never seen before.
But let’s say your training data set is slightly modified and each of the handwritten numbers also has a color—red or green—associated with it. Suspend your disbelief for a moment and imagine that you don't know whether the color or the shape of the markings is a better predictor for the digit. The standard practice today is to simply label each piece of training data with both features and feed them into the neural network for it to decide.
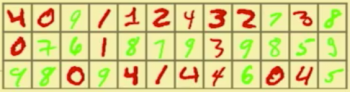
Here’s where things get interesting. The “colored MNIST” data set is purposely misleading. Back in the real world we know that the color of the markings is completely irrelevant, but in this particular data set, the color is in fact a stronger predictor for the digit than its shape. So our neural network learns to use color as the primary predictor. That’s fine when we then use the network to recognize other handwritten numbers that follow the same coloring patterns. But performance completely tanks when we reverse the colors of the numbers. (When Bottou and his collaborators played out this thought experiment with real training data and a real neural network, they achieved 84.3% recognition accuracy in the former scenario and 10% accuracy in the latter.)
In other words, the neural network found what Bottou calls a “spurious correlation,” which makes it completely useless outside of the narrow context within which it was trained. In theory, if you could get rid of all the spurious correlations in a machine-learning model, you would be left with only the “invariant” ones—those that hold true regardless of context.
Invariance would in turn allow you to understand causality, explains Bottou. If you know the invariant properties of a system and know the intervention performed on a system, you should be able to infer the consequence of that intervention. For example, if you know that the shape of a handwritten digit always dictates its meaning, then you can infer that changing its shape (cause) would change its meaning (effect). Another example: if you know that all objects are subject to the law of gravity, then you can infer that when you let go of a ball (cause), it will fall to the ground (effect).
Obviously, these are simple cause-and-effect examples based on invariant properties we already know, but think how we could apply this idea to much more complex systems that we don’t yet understand. What if we could find the invariant properties of our economic systems, for example, so we could understand the effects of implementing universal basic income? Or the invariant properties of Earth’s climate system, so we could evaluate the impact of various geoengineering ploys?
So how do we get rid of these spurious correlations? This is Bottou's team's second big idea. In current machine-learning practice, the default intuition is to amass as much diverse and representative data as possible into a single training set. But Bottou says this approach does a disservice. Different data that comes from different contexts—whether collected at different times, in different locations, or under different experimental conditions—should be preserved as separate sets rather than mixed and combined. When they are consolidated, as they are now, important contextual information gets lost, leading to a much higher likelihood of spurious correlations.
With multiple context-specific data sets, training a neural network is very different. The network can no longer find the correlations that only hold true in one single diverse training data set; it must find the correlations that are invariant across all the diverse data sets. And if those sets are selected smartly from a full spectrum of contexts, the final correlations should also closely match the invariant properties of the ground truth.
So let’s return to our simple colored MNIST example one more time. Drawing on their theory for finding invariant properties, Bottou and collaborators reran their original experiment. This time they used two colored MNIST data sets, each with different color patterns. They then trained their neural network to find the correlations that held true across both groups. When they tested this improved model on new numbers with the same and reversed color patterns, it achieved 70% recognition accuracy for both. The results proved that the neural network had learned to disregard color and focus on the markings' shapes alone.
Bottou says his team's work on these ideas is not done, and it will take the research community some time to test the techniques on problems more complicated than colored numbers. But the framework hints at the potential of deep learning to help us understand why things happen, and thus give us more control over our fates.
