Business Impact
A DNA Tower of Babel
As more and more people’s genomes are decoded, we need better ways to share and understand the data.
If the Internet cloud were actually airborne, it would be crashing down right now under the sheer weight of a quintillion bytes of biological data.
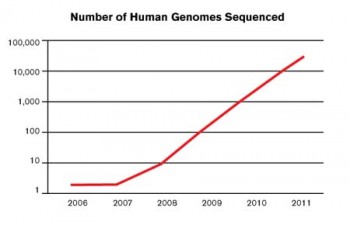
This year, the world’s DNA-sequencing machines are expected to churn out 30,000 entire human genomes, according to estimates in Nature magazine. That is up from 2,700 last year and a few dozen in 2009. Recall that merely a decade ago, before the completion of the Human Genome Project, the number was zero. At this exponential pace, by 2020 it may be feasible—mathematically, at least—to decode the DNA of every member of humanity in a single 12-month stretch.
The vast increase in DNA data is occurring because of dazzling advances in sequencing technology. What cost hundreds of millions of dollars a decade ago now costs a mere $10,000. In a few years, decoding a person’s DNA might cost $100 or even less.
But what’s missing, say a growing chorus of researchers, is a way to make sense of what these endless strings of As, Gs, Cs, and Ts mean to individuals and their health. “We are really good at sequencing people, but our ability to interpret all of this data is lagging behind,” says Eric Schadt, director of the Mount Sinai Institute for Genomics and Multiscale Biology and chief scientific officer at California-based Pacific Biosciences, which sells sequencing machines.
Scientists don’t yet know what all our DNA does—how each difference in genetic code might influence disease or the color of your hair. Nor have studies confirmed that all the genetic markers linked to, say, heart disease and most cancers actually increase a person’s risk for these illnesses. Just as significant, the thousands of genomes being cranked out right now can’t easily be compared. There is no standard format for storing DNA data and no consistent way to analyze or present it. Even nomenclature varies from lab to lab.
The industry is working to address these problems. Earlier this summer, at a meeting of geneticists and other experts that I attended in San Francisco, Clifford Reid, the CEO of Bay Area-based Complete Genomics, called for a consortium of gene companies to develop sorely needed standards for everything from consent procedures for DNA donors to methods of collecting, storing, and analyzing DNA specimens. Reid says the ultimate purpose is to “aggregate multiple data sets, providing broad access to data sets that are today in silos and largely unavailable to the broader scientific community.”
The payoff from “interoperable” genomes will be faster research on the links between DNA and disease, scientists say. Researchers will be able to validate suspected links between genetic makeup and drug reactions or overall health by conducting much larger studies in which many people’s genomes are compared. And physicians and individuals will be able to use standardized methods of reporting a person’s genetic risks and advantages. That will matter as more and more ordinary people have their DNA decoded.
Another major initiative comes from Sage Bionetworks, a Seattle-based nonprofit cofounded by Schadt and Sage director Stephen Friend, formerly the leader of Merck’s advanced technologies and oncology groups. Sage has raised $20 million to support a movement among biologists, computer scientists, patient advocacy groups, and businesses to standardize DNA databases that have sprung up over the years. “This won’t happen overnight,” says Schadt. “But it will be huge, like the Internet.”
At some companies, efforts are under way to build an IT infrastructure capable of pooling and interpreting whole genomes on a larger scale. Jorge Conde, the CEO of Knome, a company in Cambridge, Massachusetts, that sells whole-genome sequencing as a service and uses a team of PhDs in India to analyze the results, says more drug companies now want to use full genomes to understand why drugs work or have side effects in some people and not others. “As the price has dropped, we are getting more interest from pharma and biotech companies,” says Conde. Knome’s price for its sequencing and analytical service has dropped from $350,000 in 2007 to under $10,000 today.
One of Knome’s more recent ideas, still at an early stage, is to get drug companies to share genomes they have had decoded. The company has launched a cloud-based service called kGAP that would let customers process several hundred genomes at one time, studying them for the presence of 200,000 known links between DNA markers and genotypes for disease and other traits. The technology is still oriented toward facilitating big research projects, but eventually such engines might be used to compare an individual’s genome with thousands of others and spit out personalized health tips and diagnoses. “The big play is when this information is available to be used by health-care providers and patients,” says Conde. “But that’s still several years away.”
